Introduction au Web

World Wide Web
Objectif
Avant d’aborder le développement web, je pense qu’il peut être nécessaire de faire une introduction au Web, à son fonctionnement et à ses diverses couches, afin d’appréhender ce qui n’est pas toujours clair, et parfois même confus, en ce qui concerne les termes et les rôles de ce qui s'y rapporte, ainsi que pour percevoir les divers types de développements qui le composent.
Internet ou Web - Web ou Internet ?
L’internet
Internet est l’abréviation de « Inter Network » ou « InterNetworking », pour Réseaux Interconnectés, un ensemble de réseaux reliés entre eux. Un internet, quand il s'agit du nom commun, représente un réseau reliant d’autres réseaux. L’Internet, tel qu’on l’entend couramment, ou encore le Net par abréviation, représente Le Réseau principal que tout le monde connait aujourd’hui, et représente donc l’ensemble des réseaux interconnectés et accessibles, qu’ils soient publics ou privés.
L’Internet est né en 1983 et descend de l’ARPANET, un réseau militaire opérationnel depuis la fin des années soixante et conçu à l’origine pour conserver les communications et préserver l’information en cas de guerre mondiale: décentraliser l’information afin qu’elle reste disponible et accessible, quoi qu’il arrive.
Le Web
Web est le diminutif de World Wide Web. Créé en 1990, le World Wide Web, aussi appelé le WWW, ou le W3C, est un système hypertexte qui utilise l’Internet. Aujourd’hui, par manque d’informations, on considère souvent le Web comme étant l’Internet, mais ce n’est pas vraiment ça. Pour faire simple, le Web est un procole de communication et Internet est le réseau sur lequel transitent les données. Le Web utilise donc Internet pour transmettre ses données, l’Internet étant lui même lié à un protocole, le TCP/IP.
Un système hypertexte est un système qui relie des documents entre eux et qui permet de passer de l’un à l’autre par des liens appelés hyperliens ou liens hypertexte. Un hyperlien, ou lien hypertexte, est une référence à un document, à une page ou à une partie d’une page
Ce système hypertexte, le Web, permet donc d’avoir des documents reliés entre eux et qui s’affichent, sous forme de pages, dans un navigateur, accessibles par le réseau Internet. Ces documents, ces pages Web, sont reliés entre eux, entre elles, par des hyperliens. Ces pages sont écrites dans un langage de balisage, le HTML
Un hyperlien, appellé plus couramment lien, est un élément intéractif au sein des pages permettant de passer de l’une à l’autre, le tout formant un site.
Protocoles de communication
Selon l’utilisation que l’on fait d’Internet, envoyer des mails, télécharger des fichiers, lire des news..., on utilisra un protocole différent qui fera transiter l’information sur Internet. D’une manière générale, Internet utilise une suite de protocoles de communication appelés TCP/IP, pour Transmission Control Protocol/Internet Protocol, Protocole de Contrôle de Transmission de Protocole Internet, d’où sont issues ces fameuses adresses IP et qui sont associées à une machine. Internet utilise aussi le protocole UDP. C'est la nature de l’échange, de l’information qui devra transiter qui déterminera le protocole a utiliser (ce qui est transparent pour l’internaute). Pour envoyer et recevoir des e-mails, on utilisera les protocoles SMTP, POP3 ou IMAP, pour du téléchargement ce sera FTP, pour lire des News ce sera NNTP... et, pour le Web, ce sera le protocole HTTP.
HTTP/HTTPS
Le nom du protocole du Web est connu de par son acronyme, ces 4 lettres qui figurent devant les adresses Web que l’on tape dans les navigateurs: HTTP, pour HyperText Transfert Protocol, Protocole de Transfert HyperTexte, le HTTPS étant la version sécurisé de ce protocole, le S indique que les données qui transitent en HTTP sont sécurisées en étant chiffrées. Ainsi, tout ce qui aura attrait au Web sur Internet, dans un navigateur, utilisera les protocoles HTTP et HTTPS. Par convention, si le protocole n'est pas précisé lorsque l’on tape une adresse Web dans le navigateur, il utilisera le HTTP, ou HTTPS (selon la configuration du site/serveur) ajoutant lui-même l’acronyme de ce protocole devant l’adresse du site: taper google.fr dans la barre d’adresse amènera le navigateur à aller directement sur https://google.fr sans avoir à préciser HTTP(S).
Principes de fonctionnement
Client/Serveur
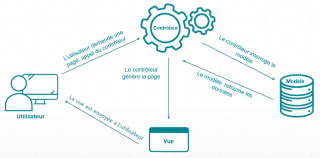
Les principes de fonctionnement du Web se raprochent de ce que l’on retrouve dans la vie quotidienne, tel qu’au restaurant par exemple, avec cette notion, ce principe de Client/Serveur: le client correspond au navigateur de l’utilisateur, l’internaute ; le serveur correspond à l’ordinateur sur lequel sont stockées les pages qui forment le site, ou l’application.
Au restaurant, quand un client commande ce qui figure sur la carte, le serveur commence par regarder si le plat est disponible et, si c'est le cas, il le sert à la table de celui qui a commandé. De même, lorsque qu’un internaute, avec son navigateur, demande une page Web au serveur, ce dernier va d’abord s'assurer que la page existe. Si la page existe, elle sera renvoyée au navigateur, le client, qui l’affichera à l’écran de l’utilisateur. Si la page n'existe pas, le serveur l’indiquera au navigateur, le client.
La demande d’un navigateur s'appelle une requête et la page retournée se nomme la réponse

Le client demande une page, le serveur vérifie qu’elle existe, la récupère et la renvoie
Chaque appel de page est une requête, une demande effectuée au serveur, que ce soit en cliquant sur un lien, ou en tapant directement l’adresse du site dans la barre d’adresse du navigateur.
Quand une page n'existe pas, le navigateur reçoit une page d’erreur de type 404, cette fameuse page qui indique que la page n'a pas pu être trouvée. Cela indique toujours que la page demandée n'existe pas, ou n'existe plus. Cependant, il arrive que la page souhaitée existe mais que l’internaute ait fait une faute dans l’écriture du nom de cette page, demandant un mauvais nom, tapant une mauvaise adresse. Le serveur, lui, ne fait pas le rapprochement entre le vrai nom de la page souhaitée et le nom avec la faute qui aura pu être faite, il cherchera la page avec le nom correspondant à ce qui lui aura été demandé, avec la faute, ce qui indiquera une page qui n'existe donc pas
Il ne faut pas confondre effectuer une recherche en tapant des mots, que ce soit dans la zone de recherches ou dans la barre d’adresse, avec écrire une adresse Web dans la barre d’adresse: taper « site google.fr » affichera une page de résultats avec différentes pages du site Google. Taper « google.fr » dans la barre d’adresse affichera le site https://google.fr
Autant le navigateur, en lien avec le moteur de recherche et son historique, peut faire de la prédiction en proposant des mots, des adresses de sites en fonction de la saisie, autant le serveur ne choisira pas une page avoisinant le nom de celle écrite avec une erreur. Taper une adresse dans la barre d’adresse indique vouloir s’y rendre, taper des mots, une phrase, indique faire une recherche sur ces critères. Ainsi, le navigateur ne vous enverra pas vers le bon site en corrigeant un mauvaise adresse à votre place, c’est du moins le fonctionnement initial du protocol de communication...

Erreur 404 - La page demandée n'existe pas
D’une manière générale, un serveur s'exprime par des codes, des codes qui indiquent la situation, 200 si tout va bien ou, au contraire, un code indiquant s'il y a eu une quelconque erreur ou un quelconque problème, ces codes étant ensuite interprétés pour donner une message, une indication à l’utilisateur. C'est le cas pour le code 404, qui indique que la page n'existe pas. Liste des codes HTTP

Les Serveurs sont prévus pour gèrer un nombre important de requêtes au même instant
Le Serveur et les page Hypertextes
Ce sont l’ensemble de ces pages pages hypertextes, reliées entre elles et stockées sur cet ordinateur distant qu’est le serveur, qui formeront le Site Web ou encore l’Application Web. Ces pages sont stockées dans un dossier dont le contenu, organisé en sous-dossiers, forme le Site ou l’Application Web.
Evolution du Web
Sans rentrer dans les détails du fonctionnement du site et de l’application Web, je vais rapidement aborder les deux versions majeures du Web, et les suivantes, afin de mieux en percevoir l’évolution.
Le Web 1.0
Initialement, on ne parlait pas vraiment de version pour le Web. Ce n’est que par l’évolution des techniques de développement, qui ont ouvert un autre mode de fonctionnement côté navigateur, donnant naissance au Web 2.0, que l’on a commencé à parler du Web 1.0, mais au départ on ne parlait que du Web sans distinction.
Il ne faut pas confondre les versions du Web tel qu’on l’entend et les versions du protocole HTTP
- Un Web statique
Le Web originel, le Web 1.0, n’était constitué que de pages dites statiques, c’est à dire non interactives, avec une communication synchrone avec le serveur. Non interactive n’est pas tout à fait ça puisqu’il était possible d’exercer une action, un click sur un lien, sur un bouton, des choix dans des listes, avec des cases à cocher.... Lorsque l’internaute consultait une page, il pouvait la faire défiler, lire son contenu, avoir un minimum d’interaction avec au travers les formulaires, mais dès l’instant qu’il effectuait une action qui demandait la modification de la page ou d’une partie de la page en interrogeant le serveur, la demande de nouvelles données faisait qu’il n’était plus possible pour l’utilisateur de faire une quelconque opération sur la page tant que la réponse du serveur n’était pas retournée. D’une manière générale, la demande de données non comprises dans la page demandait le rechargement complet de cette dernière, ou en appelait une autre: la communication entre le client et le serveur était synchrone et bloquante, c’est à dire que le navigateur ne pouvait plus rien faire tant qu’il n’avait pas reçu la réponse du serveur, d’où la notion de synchrone, pour synchronisation. De là, on ne devait pas cliquer à tort et à travers, car un simple click pouvait amener des temps d’attente, souvent interminables, pour le rapatriement des données du serveur du fait de la lenteur des connexions Internet de l’époque.

Tant que le navigateur n'avait pas reçu la réponse du serveur, la navigation était bloquée au sein de la page
Aujourd’hui, avec la fibre optique les débits pour les particuliers vont de 1 à 2 Gigabits, en théorie, 8 pour Free (il faut 8 bits pour 1 octet, ainsi 1 Giga bit/s = 128 Méga Octets/s soit 128 Méga Octets par seconde). L’ADSL va de 20 à 96 Mégabits (soit ente 2,5 et 12Mo/s). Mais dans les années 90, les années du Web 1.0, ce n'était pas la même chose, les débits étaient tout autre. En 1994, la norme était de 14,4kb/s (1,8ko/s) pour atteindre, en 1995 les 56Kb/s (7ko/s), voir jusqu’à 128kbits/s (16ko/s) pour les modem RNIS de base. En 1999 arriva la première ADSL, avec 512k, puis l’ADSL2+ en 2004 pour 16Mbits/s. Tout cela pour dire que selon les époques, comparé à aujourd’hui, télécharger une pièce jointe d’1Mo avec un modem 14.4k pouvait prendre jusqu’à 9 minutes 1/2 et 2 minutes 1/2 avec un modem 56k, pour moins d’un centième de seconde aujourd’hui. Il valait donc mieux réfléchir à 2 fois avant de cliquer n’importe où
Le Web 2.0
Dans le début des années 2000, vers 2003, on a commencé à parler du Web 2.0. Il s’agissait de pouvoir interagir avec des pages Web qui n'étaient plus statiques, toujours côté navigateur. La révolution tenait dans le fait de pouvoir recevoir des données du serveur pour mettre à jour la page sans avoir à la recharger complètement et sans qu’elle ne soit bloquée, laissant un large évantail de possiblités en terme d’interactions utilisateur. Cela a permit d’avoir des sites où les utilisateurs ont commencé à pouvoir interagir avec les pages, donnant naissance à des applications en ligne, aux réseaux sociaux, donnant la possibilité de construire des blogs... et a donné, dans le temps, naissance au Web interactif tel qu’on le connait aujourd’hui.
- Le Web interactif
Le Web 2.0 a été rendu possible grâce à une « technique » du langage JavaScript mise au point par Microsoft entre 1997 et 1998, la bibliothèque (ensemble de fonctionnalités) HttpXmlRequest, plus communément appelée AJAX, pour Asynchrone JavaScript Apache XML, une communication non synchronisée entre le navigateur, par le langage JavaScript, et un serveur Apache pour recevoir des données au format XML, le grand frère du HTML. Cette technique, AJAX, permet au navigateur de communiquer de manière asynchrone avec le serveur, sans bloquer la page actuelle, tout en permettant à l’utilisateur de continuer sa navigation, de pouvoir continuer d’interagir avec le contenu et même d’effectuer d’autres requêtes au serveur. Cela permet de changer une ou plusieurs partie(s) d’une page sans avoir à la recharger et sans avoir à attendre le retour du serveur pour continuer d'’interagir avec, tel que par exemple écrire un commentaire sur Facebook, y joindre une image, le poster (l’envoyer au serveur) et qu’il soit incorporé à la page sans avoir à la recharger.
Un autre exemple: sur la page d’un e-commerce on souhaite affiner la recherche, parmis les articles qui figurent dans la liste des résultats, en sélectionnant des critères tel que le prix, la couleurs, la taille, le fabriquant.... Le navigateur envoie une requête au serveur en transmettant les critères de filtres. Le serveur interroge la Base De Données avec ces critères. La Base De Données retourne au serveur tous les articles qui correspondent à ces critères. Le serveur renvoie ces articles au navigateur. Une fois les données récupérées, le navigateur modifie, reconstruit, adapte la page en fonction des données retournées. Il n'y a que si l’utilisateur change de page en court de route, ou déclenche une autre action coupant la première, que la requète est interrompue, sinon l’affichage des articles se fera selon les critères de choix. De son côté, le navigateur continue de fonctionner normalement pendant le temps que le serveur renvoie les données (asynchrone indique que le navigateur n'attend pas la réponse du serveur pour permettre à l’utilisateur de continuer d’interagir avec la page). Bien sûr cela va très vite, bien que cela dépende de la vitesse de connexion et de la qualité des programmes développés en amont.
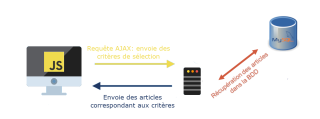
Le navigateur interroge le serveur et n’est pas bloqué en attendant la réponse
Les fondations du Web 2.0 tiennent sur le fait de pouvoir envoyer et recevoir des données en interrogeant, de manière asynchrone, le serveur qui renverra les informations demandées au navigateur pour qu’il adapte la page actuelle
Asynchrone indique que le navigateur n'aura pas besoins d’attendre que les données demandées au serveur soient retournées pour que l’utilisateur puisse contiuner sa navigation, que ce soit la validation d’un formulaire ou la demande de données complémentaires
L’asynchrone permet d’interroger des services que l’on appelle des API. J’en parlerai plus tard...
Les Promises ou Promesses
Les promesses, ou Promises, sont la continuité du Web asynchrone. Bien que l’on ait tendance à noter les évolutions du Web par différentes versions successives, le fondement même de l’évolution du Web tient vraiment dans le côté asynchrone des requêtes dont les Promises apporte un niveau supplémentaire.
Le but n’est pas de lister toutes les technologies ayant fait évoluer le Web technologiquement parlant
Le Web Sémantique ou Web 3.0
Ce que certains définissent comme le Web 3.0 se définie comme un Web Sémantique. Il s'agit d’être plus axé sur l’Information et ses qualités, sur les données en soit et d’en assurer la cohérence. On parlera de métadonnées, des données sur les données afin de les décrire. Cela permet de traiter l’Information avec précision, avec certitude, sans incohérence et sans tromperie. Le Web Sémantique permet la mise en relation des données inter sites/applications et d’en assurer la pertinence. « Le but sera ainsi dans l’avenir d’améliorer l’accès et l’utilité du Web et des ressources interconnectées à travers lui » - Wikipédia -. La blockchain, tel que pour les cryptomonnaies ou les droits d’auteur, en est un exemple.
- Datas et Applis
La mise en relation des données permet l’interconnexion à l’Information par diverses applications. Le Web 3.0 a aussi une notion d’Expérience Utilisateur et de lien avec les objets connectés, du smartphone au bracelet, en passant par la TV... Le Web3 se porte aussi sur le cloud, le stockage des données en ligne et accessibles de partout.
Le Web Sémantique permet l’interconnexion entre les Bases De Données de diverses entreprises, organisations, sites..., donnant la possibilité de croiser ces données et d’obtenir l’Information recherchée d'’une manière plus précise, ou étendue. Un site qui interroge plusieurs sources peut ainsi servir l’Information avec plus de pertinence
Exemple: Vous recherchez un hôtel pour une période définie. Le Web Sémantique donne la possibilité de faire une recherche sur un site de réservation en ligne qui ira interroger, en quelques secondes, voir quelques dizaines de secondes, tous les autres sites que vous auriez pu interroger en plusieurs dizaines de minutes, voir bien plus en vous perdant dans la multitude de choix, afin de récupérer les propositions de chacun, selon vos critères, pour vous proposer les hôtels disponibles, voir les horaires de train et tout ce qui pourra être proposé en termes de critères de recherche en rapport avec la recherche initiale
L’IA ou le Web 4.0
Certains parlent du Web 4.0 en parlant d’un Web ultra intelligent, d’autres ne parlent « que » d’intelligence. En pleine effusion, il est axé sur tout ce qui a attrait à l’IA, l’Intelligence Artificielle, la robotique, le machine learning (l’apprentissage automatique par les ordinateurs), la réalité augmentée et, bien entendu, les objects connectés puisque c'est ce qui nous y relie, aux données et aux processus qui les traitent.
- Intelligent ou envahissant ?
L’analyse des habitudes, du comportement pour mieux connaitre, mieux cadrer l’utilisateur et correspondre au mieux à ses attentes, à ses demandes n’est pas toujours bien perçu, et à juste titre, mais là n’est pas le sujet. Bien qu’omniprésent, ce Web a pour vocation à être plus discret, puisqu’il est censé travailler en tâches de fond pour apprendre de sur l’utilisateur, de part ses habitudes en tous genres, déplacements, saisies, orations, habitudes d’achats..., afin de pouvoir répondre au mieux possible aux attentes de, et aux propositions à faire à, l’utilisateur.
Difficile d’aborder ce sujet sans donner l’impression d’être rétrograde ou, au contraire, d’être laxiste. Cependant, les champs d’applications du machine learning, pour ne parler que de ça, permettront, et permettent déjà, de bonnes choses en soit. Par exemple, un système d’aide à la conduite qui apprendra à connaitre et reconnaitre la route à prendre selon les habitudes de son utilisateur, qui pourra choisir un restaurant sur la simple demande du « conducteur », selon ses goûts et ses habitudes, et l’y emmènera sans qu’il n'ait à conduire...
Le Web, oui, mais encore
Les différentes couches
Le Web ne correspond pas qu’à une simple zone, au contraire. La zone complète du Web est divisée en différentes couches, certaines étant accessibles d’une manière particulière et inaccessibles sans le vouloir, sans faire ce qu’il faut pour.
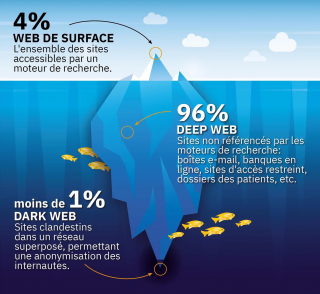
Les 4% ne sont qu’une estimation de ce qui est référencé par les moteurs de recherches, ce vers quoi les gens sont dirigés
Le Web de surface
Le Web, tel qu’on le connait d’une manière générale, est ce que l’on pourrait décrire comme la partie commerciale ou publique du Web, plus couramment appelée la partie émergée. Il s’agit en fait du SurfaceWeb, Le Web de Surface. Cette partie du Web est celle dont les sites sont indexés par les moteurs de recherches, tel que Google, Qwant, Yahoo, Bing, DuckDuckGo... de façon à être trouvés lors de recherches: ce sont les sites qui sont proposés par ceux qui « contrôlent » le Web ; contrôle dans ce cas étant plutôt un contrôle dans le sens de la pertinence et de la qualité de l’information, et non pas dans le sens que l’on ne puisse pas faire d’autres choix que ceux qu’ils proposent, encore faut il vouloir, ou avoir le temps de dépasser la ou les premières pages de résultats. D’une manière générale, il est concevable que les sites soient recensés, répertoriés et classés par des notions de qualité et de pertinence de l’information, et bien entendu pour des raisons de sécurité. Ainsi, qu’un site se retrouve en première ou en dernière position dans les résultats d’un moteur recherche, tant qu’il y est, c’est qu’il est indexé, référencé (le positionnement et l’indexation seront abordés dans la partie SEO).

L’indexation, pour un site ou une application, est le fait d’être recensé, référencé par les moteurs de recherches, Google, Bing, Yahoo, DuckDuckGo ou encore Qwant (le moteur de recherche français), en sachant que celui qui fait la loi, ou bat la mesure, depuis des années reste Google
Ainsi, tant que l’on n’indique pas aux programmes d’indexation des moteurs de recherches que l’on ne souhaite pas être référencé, un site ou une application se retrouvera indexé, et classé, référencé, comme plus ou moins bon, selon la qualité de sa structure et de la pertinence de son contenu. Ces programmes d’indexation sont ce que l’on appelle les robots d’indexation (les crawler en anglais) et dressent la liste des sites référencés, recensés selon des critères, selon le ou les sujets traités et classés selon leurs qualités en termes de structure/programmation/efficacité. Le Surfaceweb, c’est le Web que tout le monde connait: une recherche dans Google et on vous présente une liste de sites qui correspondront au mieux à ce que vous aurez tapé comme demande, comme requête, comme sujet de recherche, classés par ordre de pertinence dirons nous, ce qui est du domaine du SEO, Search Engine Optimization, Optimisation pour les Moteurs de Recherche.
Le Web Profond ou DeepWeb
Bien qu’il existe une réelle confusion entre le DeepWeb (le Web Profond), le DarkWeb (le Web Sombre) et les DarkNets, l’un et l’autre ne sont pas pareils.
Le DeepWeb est toujours le Web, et avec des sites légaux, mais ce sont des sites qui ne sont pas indexés par les moteurs de recherches. Ce sont en général des sites qui se passent de la promotion des moteurs de recherches, ou des applications Web privées. Cela peut être des sites d’entreprises, des réseaux sociaux, des forums, des sites de collectivités, mais aussi des sites de recherches à thème, des sites de banques, des sites du gouvernement, d’universités... tous types de sites à vrai dire, mais qui ne souhaitent pas, ou ne doivent pas, être recensés par les moteurs de recherches, peu importe leurs raisons. Bien entendu, on parle toujours de sites légaux. Il peut aussi y avoir des sites référencés qui ont des parties qui ne le sont pas: par exemple, si vous ne souhaitez pas que l’on retrouve votre page Facebook dans Google, il suffit de le préciser dans les paramètres pour que votre page ne soit pas, ou ne soit plus, référencée. De même, la partie Back-Office d’un site (l’interface de gestion) n’est généralement jamais référencé, sans que cela ne soit illégal, je le précise encore car DeepWeb n’est pas synonyme d’illégalité.

Le DeepWeb fonctionne toujours avec le protocole de communication HTTP(S) et fait donc partie du Web
Il faut savoir que des sites indexés par Google peuvent aussi contenir des virus et autres programmes indésirables, même s’ils font tout pour l’éviter. On ne peut donc pas prétendre que le Web soit plus sécurisé que le DeepWeb, surtout que des sites d’apparence « propres » peuvent vous proposer, en interne, des liens vers des sites non référencés qui comportent des virus...
Sans le savoir, vous avez certainement déjà visité un site qui n’était pas référencé, donc faisant partie du DeepWeb.
Le Web Sombre ou DarkWeb
Le DarkWeb est tout autre chose. Bien que le DarkWeb fasse partie du DeepWeb, donc du Web, il fonctionne tout autrement. C’est cette partie du Net dont on a si souvent entendu parler pour pouvoir y acheter de la drogue, des armes, des films malsains, ou encore trouver les services d’un tueur à gages, ce que beaucoup décriraient, avec raison, comme le mal, ou encore trouver les services de hackeurs, éthiques ou pas...

Mais le DarkWeb ce n’est pas que ça. Le DarkWeb donne aussi la possibilité à des reporters de guerre, des journalistes d’investigation, de protéger leurs échanges, d’éviter la censure, de communiquer librement dans l’anonymat ; c’est aussi la possibilité pour des donneurs d’alertes de communiquer d’une façon sécurisée à propos de sujets sensibles tout en se préservant de la surveillance, ceux qui recherchent une certaine protection, ou un anonymat, tel qu’Edward Snowden, par exemple, qui a été lanceur d’alerte vis-à-vis de la NSA et de la CIA, aux USA.
De par son mode de fonctionnement de l’ordre de l’anonymat, le DarkWeb ne permet pas aux sites d’identifier les internautes par leur adresse IP, tout comme il ne permet pas aux internautes d’obtenir des informations pertinentes sur les sites qu’ils consultent. De ce fait, il s'agit d’un lieu plutôt anonyme et c'est peut être la raison pour laquelle il a beaucoup été blâmé, au-delà de ce qu’il aurait dû l’être de par les activités illégales que l’on peut y retrouver: par exemple, pas de possibilité de faire du profilage d’utilisateur dans un but commercial, tel qu’on le retrouve sur le SurfaceWeb avec des sites tels que Facebook, Google, Pinterest et des tas d’autres qui cherchent à établir votre profil au fil de vos visites, les sites se relayant les informations entre eux via des cookies et les boutons « Like » ou « J’aime » que les créateurs de sites insèrent dans leurs pages et qui récupèrent des informations sur leurs utilisateurs.
Le Dark Web permet essentiellement de rendre possible la liberté d’expression, d’information et d’échange total fondé sur la sécurité de l’anonymat, et permet donc à chacun de lire comme de publier du contenu. On y trouve ainsi beaucoup de ressources légales, qui y sont cachées pour lutter contre la censure. - Wikipédia -
Le côté anonyme et « respectueux » de la vie privée ne retire par au DarkWeb son côté sombre de par les sites illégaux qu’il héberge, c’est un fait, mais on ne tombe pas sur ces sites par hasard, il faut le savoir
DarkWeb et DarkNet
Quoi qu’il arrive, on ne va pas sur le DarkWeb sans le vouloir. Le DarkWeb utilise d’autres réseaux, que l’on nomme des DarkNets. Un DarkNet est donc un réseau, avec son protocole de communication qui n’est plus le HTTP. Pour accéder à un DarkNet, il faut installer la partie logicielle, qui comprend le protocole de communication utilisé et qui permettra de se connecter au réseau DarkNet, ainsi qu’un navigateur particulier, qui permet d’y naviguer, tel que TOR et TOR Browser, le protocole et le navigateur les plus connus.
Dans le cas de ce DarkWeb, TOR est le DarkNet et TOR Browser est le navigateur qui permet d’y accéder. Et bien que le Web de Surface soit accessible par TOR, le DarkNet TOR n’est pas accessible par les navigateurs traditionnels. Pour en savoir plus.
Et l’Intranet qu’est ce que c'est ?
L’Intranet ou le Net interne - privé
L’Intranet se comporte comme le Net normal, à une différence près: c'est qu’il est propre au réseau interne d’une entreprise, d’une collectivité ou d’une organisation, c'est un réseau privé. Là où l’Internet se tourne vers le monde extérieur, le monde tout court, l’Intranet se cantone au monde interieur de l’entreprise, de la collectivité ou de l’organisation, avec bien sûr la possibilité d’avoir des accès contrôlés vers le Net externe, l’Internet. L’Intranet ne se limite pas obligatoirement au seul réseau local de l’organisation, il peut s'étendre aux différents réseau locaux de chacune de ses succursales, que ce soit au sein d’une ville, d’une région, d’un pays ou au travers le monde. Ainsi, une entreprise, une organisation ou une collectivité, qui est implantée dans diverses villes, régions et/ou pays, peut avoir son propre réseau interconnecté. Au niveau d’une ville, sur une distance de 100km maximum, on parlera d’un MAN, Metropolitan Area Network, pour Réseau Métropolitain. Sur une échelle plus grande, tel qu’au niveau d’un pays ou au niveau mondial, on parlera de WAN, Wide Area Network, pour Réseau Grande Distance, les deux permettant de relier les Réseaux Locaux, les LAN, pour Local Area Network tel que le réseau d’une box.
Il existes un certains nombre de types de réseaux avec leurs topologies, et le but n’est pas de les traiter, mais juste d’expliquer simplement qu’il est possible, et courant pour les grandes entreprises, de relier entre eux les différents réseaux locaux de chaque succursale, et de créer un Intranet, un Net interne à l’entreprise. De plus, ce Net interne peut être rendu accessible de l’extérieur de manière rigoureusement contrôlée et réglementée via une connexion par VPN et une authentification. Le VPN, Virtual Private Network pour Réseau Privé Virtuel, peut être vue comme un tunnel qui permet d’établir une connexion chiffrée et sécurisée entre un ordinateur et le serveur d’un réseau, permettant et garantissant ainsi un accès totalement privé et sécurisé pour permettre, par exemple, à des employés d’accéder à l’Intranet lors de déplacements ou à partir de chez eux. L’Intranet est généralement mis en œuvre par de grandes entreprises, ou organisations souhaitant un Net interne, ce qui représente un coût.

Dans l’absolue, l’interconnexion des réseaux locaux n’est pas exclusivement réservé qu’aux organisations. Une famille pourrait très bien avoir les réseaux locaux de chaque foyer, donc de chaque box, reliés entre eux. MAN ou WAN, selon la distance des foyers, avec un ou plusieurs site(s), ce qui formerait l’Intranet familial. Ceci juste pour indiquer que tout est réalisable
Les avantages d’un Intranet
Les avantages d’un Intranet pour une organisation, entreprise ou collectivité sont certains, mais la gestion de l’infrastructure est quelque chose de particulièrement pointue. Pour toutes structures qui a un réel besoin de communiquer en interne en toute sécurité, tel que pour des laboratoires scientifiques, des organisations humanitaires, des églises, des associations ou tous types d’entreprises, l’Intranet, s'il est justifié, est une bonne solution en soit pour diffuser de l’information, communiquer et travailler sous formes de sites et d’applications, en interne.
Le LAN
Le Réseau Local
Un LAN, Local Area Network en anglais, est ce que l’on appelle un Réseau Local, le réseau de base que l’on retrouve un peu partout de manière privée, qu’il ne s’agisse que d’un ordinateur relié à une box ou de tous les PC d’une entreprise ou d’un foyer. Depuis l’arrivée des Box, à l’origine par Free et leur première Freebox avec routeur en 2004, il est devenu facile pour chacun d’avoir son propre réseau local. Avant, il fallait, par exemple, configurer une machine comme serveur, le pc sur lequel était connecté le modem, permettant la connexion à Internet, et sur lequel il fallait installer un logiciel pour partager la connexion, puis, soit relier les ordinateurs entre eux quand il s’agissait d’un réseau BNC, soit les connecter à un matériel de « centralisation », HUB, SWITCH, Routeur..., permettant de les relier entre eux pour un réseau en RJ45... Bref, il fallait faire un minimum de choses. Aujourd’hui, ce sont les Box qui jouent les rôles de Serveur, Routeur, HUB, Switch..., dans une certaine limite, et permettent, via leurs fonctionnalités natives, la mise en réseau simple avec accès à Internet, faisant que chacun à d’emblée son LAN, avec plus ou moins de fonctionnalités à disposition selon la Box.

Une Box = un LAN
Boitiers SFP
Les Box comportent toute fois des limites en termes de connexion cable, connexion RJ45, et le Wifi n'est pas ce qu'il y de plus rapide, bien qu'ayant évolué, les débit ne sont pas aussi élevés que par cable. Et il y a des personnes qui ne veulent pas avoir la Wifi chez eux, la raison est un autre sujet. Ainsi, il existe une solution intéressante pour diffuser la fibre un peut partout dans la maison. Il s'agit de connecter un boitier, appelé convertisseur de média SFP, à une prise RJ45 de la Box, avec un adaptateur, boitier qui s'occupera de convertir la connexion qui sort de la box normalement en RJ45 (cuivre) en fibre optique (verre). Ce boitier devra être relié à un second convertisseur de média SFP, via un cable fibre optique, pour une distance de base 500m, certains pouvant atteindre les 20km. Le second boitier recevra la fibre comme s'il était lui même accorrdé à la prise mural au lieu de la Box et pourra redistribuer la connexion, soit en étant connnecté directement à un PC, soit, de préférence, connecté à un Switch Multiport Ethernet (une multi prise en quelque sorte). Cela permet de connecter, selon le modèle, plusieurs périphériques réseau, tels que des ordinateurs, avec un bon débit, bien au dessus du Wifi. En gros, cela permet de transmettre la fibre optique un peut partout dans la maison, dans l'entreprise, avec des débits de 1 à 10Go. L'avantage est certain car la prise fibre optique du FAI (Fournisseur d'Accès à Internet) est installé à un endroit fixe, que l'on ne peut plus déplacer une fois installée, ce qui oblige ensuite, quand on veut utiliser le réseau dans d'autres pièces, à soit devoir utiliser le Wifi, qui est le moins rapide, même avec des répétiteurs, soit utiliser les boitiers CPL, ce qui reste une bonne solution, ou soit tirer des cables RJ45 un peu partout, avec ou sans goutière, dans les murs ou dans les pleintes. Dans ce cas, avec les convertisseurs de média SFP, c'est pouvoir transporter la fibre n'importe où avec à un bout la Box et à l'autre un Hub ou un Switch multiport. Cela permet d’avoir une bonne connexion en termes de rapidité en démultipliant les connexions RJ45. Le boite SFP permet aussi de pouvoir transmettre la fibre d’un bâtiment à un autre...